
Machine Learning and Parking Availability
Do you have a lot of data that you were collecting many years and now you consider doing some magic by applying Machine Learning? What are you able to achieve with the data you have?
In this post I’ll summarize our experience of trying to apply Machine Learning during the hackathon.
In the beginning we will take a look at the problem. After that there will be a small refresher/introduction into Machine Learning and its methods. Then we choose an appropriate method that supposed to solve the problem. Once we know the method, we will figure out what data do we need and what data are actually available. In the end as a bonus, we will consider slightly different approach and will reason about it’s pros & cons.
Problem
During the hackathon we tackled a parking availability problem that was stated as follows:
As a customer I want to search for parking in a specific area and get insight if there are spaces available? Show our customers parking prediction per street/area using our transaction history.
The first solution that popped up in our technology driven minds was Machine Learning.
Machine Learning
What do we know about Machine Learning?
Machine learning is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it..
(c) Someone smart and funny
What we want essentially is that our program learns how to solve a problem itself by discovering hidden patterns in the training data set.
There are following types of learning methods available to solve different types of problems:
- Supervised learning for predictions and classifications
- Unsupervised learning for clustering and associations
- Reinforcement learning for learning from experiments
What these methods do is train a model that can either predict, classify, associate etc. In other words the model is an outcome of a learning process.
As we can see above, to be able to make predictions about parking availability we need to utilize supervised learning to train our model.
Supervised learning
How does the supervised learning works? In supervise learning we perform following steps to train our model:
- initialize a model with random parameters
- ask model to make predictions based on an input data
- evaluate the prediction based on known output
- adjusts model’s parameters to minimize the error
The key point is that we must know the prediction(output) for each input in the training data set. This paired data of inputs and results is named labeled data.
The classical example of labeled data for supervised learning is a data set of labeled images with dogs and cats. We know who is pictured on each image: a cat or a dog.
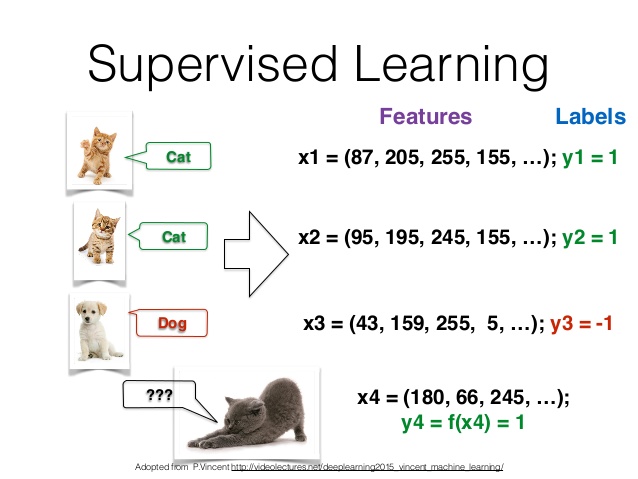
The knowledge of the output allows us to train the model in supervised manner.
Parking Availability Training Data Set
Now let’s try to answer the question - how our training data set should look like so that we could predict parking availability?
The output data should be either parking is available or unavailable. It can have different forms of course - binary(yes, no), or probability of availability(87% is available), or something else.
The input data should have features that influence parking availability.
Desired data set could look like this:
| input curLat, curLon, destLat, destLon, day, minute |
label (output) availability |
|---|---|
52.3485772, 5.0082082, 52.356612, 4.895434, 244, 772 |
true |
52.3485241, 5.0082011, 52.356278, 4.995423, 345, 631 |
true |
52.3485789, 5.0082022, 52.353972, 4.995412, 134, 1083 |
false |
52.3489271, 5.0082082, 52.356129, 4.993729, 245, 890 |
false |
52.3485772, 5.0082090, 52.356605, 4.995392, 64, 402 |
true |
Important part of the data set is the availability labels. The labels reflect the availability situation whether the parking was available(true) or unavailable(false) at the given time in the given location.
Do we have these labels in provided data set?
Cashless Parking Providers and data
What data do we have in reality? As the problem states - we need to give a prediction based on transaction history. These transaction history comes from a cashless parking provider(CPP) and basically are payments for parking in a particular zone at particular time.
Clients of CPP use the provided services once they are parked and want to pay for the parking. Therefore CPP receives transactions only for successful parking - client managed to park in a particular area, thus parking was available.
What data we don’t have is the data about unsuccessful parkings because we don’t know where the client wanted to park initially. It is possible that the client wanted to park in one place but it was completely full so he ended up parking in another place far away from the initial destination point. In other words - client dealt with unavailable parking but this data was not captured.
Disclosure: all the data is anonymized according to the GDPR.
Conclusion
The conclusion is that the transactions cannot be used as labeled training data set to train a model to predict parking availability.
Main outcome was that the CPP should start collecting feedback from the users with regard to the parking experience. Simple questions can be asked after user parked:
- Have you parked where you initially wanted?
- How long did it take to park?
- Do you see more available parking spots nearby?
This feedback will allow building labeled training data set that will not depend on city specifics.
Bonus
Availability = Amount of Free Spots?
Can we derive availability from the amount of free parking spots? Whenever we can say that there will be X parking spots free, we can say that parking in the area is available.
In order to train our model to predict amount of free parking spots, our desired labeled training data set should look like:
| input curLat, curLon, destLat, destLon, day, minute |
label (output) amount of free parking spots |
|---|---|
52.3485772, 5.0082082, 52.356612, 4.895434, 244, 772 |
23 |
52.3485241, 5.0082011, 52.356278, 4.995423, 345, 631 |
68 |
52.3485789, 5.0082022, 52.353972, 4.995412, 134, 1083 |
0 |
52.3489271, 5.0082082, 52.356129, 4.993729, 245, 890 |
0 |
52.3485772, 5.0082090, 52.356605, 4.995392, 64, 402 |
45 |
In order to label the data we should know amount of free parking spots. The math here is pretty simple:
- Estimate a \(Capacity\) of the parking area. As the capacity we can consider a historical maximum amount of simultaneous parking transactions at the area.
- Amount of \(Occupied\) spots is amount of simultanious transactions for a given time and location.
- \[Free = Capacity - Occupied\]
Accuracy of Free spots prediction
The accuracy of such model will depend on several factors and will vary per city.
Do we have all transactions in a City? If we don’t we cannot estimate a capacity of a parking location and how many spots are occupied.
Does enforcement work good? In worse case (when there is no enforcement)drivers won’t pay for parking. This will lead to situation where we see that there are 5 free parking spots, however they are occupied without paying.
Transactions reflect exact parking duration? There are cases when driver buys 20 minutes to park but leaves after 10 minutes. In couple minutes this spot gets occupied by another car that also creates a transaction. That can influence our estimations of parking space capacity by making it bigger.
Are there special tariffs? In a case when residents don’t pay for the parking they will occupy a spot but it will not create a transaction. In residential area we will see many free spots that are occupied by residents in reality.
graph TD
start --> K{Major provider?}
D{Enforced?} --> |Yes| F{Buy time?}
D --> |No| B
K --> |No| B[Incomplete]
K --> |Yes| D
F --> |Yes| G[Inaccurate]
F --> |No| H[Complete]
It worth mentioning that attempt to predict amount of free parking spots in a parking location in Amsterdam (where we didn’t have majority of all the transactions) resulted in weird numbers that exceeded amount of historical maximum of simultaneous parking actions.